MapReduce 配置与操作

一、通过eclipse连接hadoop
1. 主要步骤
-
安装eclipse
-
安装Hadoop-Eclipse-Plugin
-
配置Hadoop-Eclipse-Plugin
参考资料已给出此部分详细步骤,因此此处不再展开,仅给出实现效果如下:
2. 参考资料
3. 遇到的问题
-
新添加的插件在Eclipse中不显示
-
解决方法
在
eclipse/configuration目录下的config.ini文件中加入一行 :osgi.checkConfiguration=true,这样它就会寻找并安装插件。 -
参考资料
-
二、WordCount示例
1. 主要步骤
参考资料已给出此部分详细步骤,因此此处仅列举出主要步骤。
-
新建项目
-
在项目的src目录下创建
WordCount.java类,内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65package Package;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} -
在项目的src目录下创建
log4j.properties文件,内容如下:1
2
3
4
5
6
7
8# Configure logging for testing:optionally with log file
#log4j.rootLogger=debug,appender
log4j.rootLogger=info,appender
#log4j.rootLogger=error,appender
#\u8F93\u51FA\u5230\u63A7\u5236\u53F0
log4j.appender.appender=org.apache.log4j.ConsoleAppender
#\u6837\u5F0F\u4E3ATTCCLayout
log4j.appender.appender.layout=org.apache.log4j.TTCCLayout -
配置运行参数
-
运行
2. 运行结果
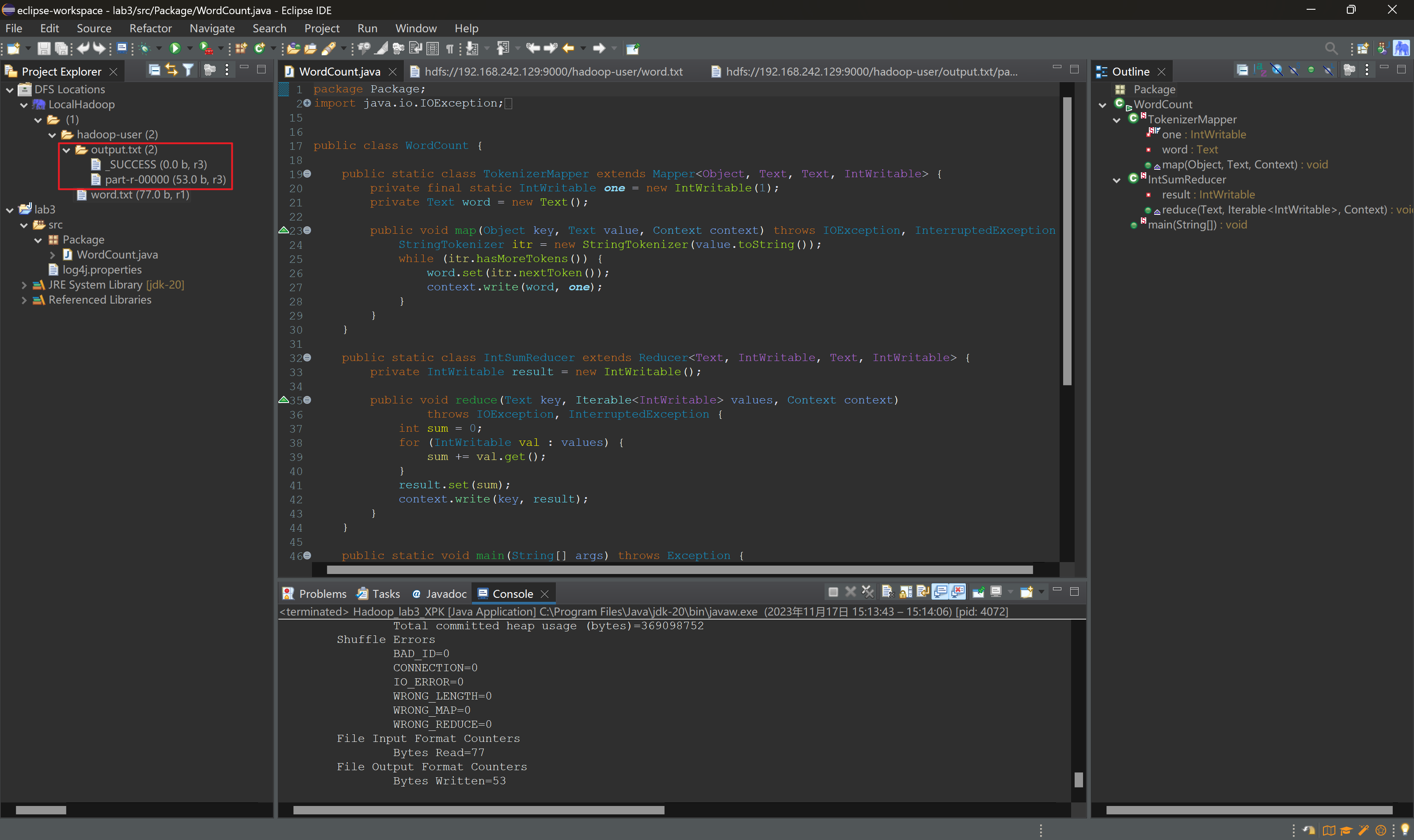
其中,word.txt 文件内容如下:
1 | a |
程序输出 hdfs://192.168.242.129:9000/hadoop-user/output.txt/part-r-00000 文件内容如下:
1 | ! 2 |
词频统计结果无误。
3. 参考资料
4. 遇到的问题
-
环境变量问题
1
Exception in thread "main" java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
-
问题分析
从错误信息中可以看到,Hadoop在执行
Shell.getWinUtilsPath的时候抛出了异常。这是因为Hadoop在进行某些本地文件系统操作时,依赖于一些环境变量,其中包括HADOOP_HOME。这两个变量都没有被正确设置,导致了FileNotFoundException。 -
解决方法
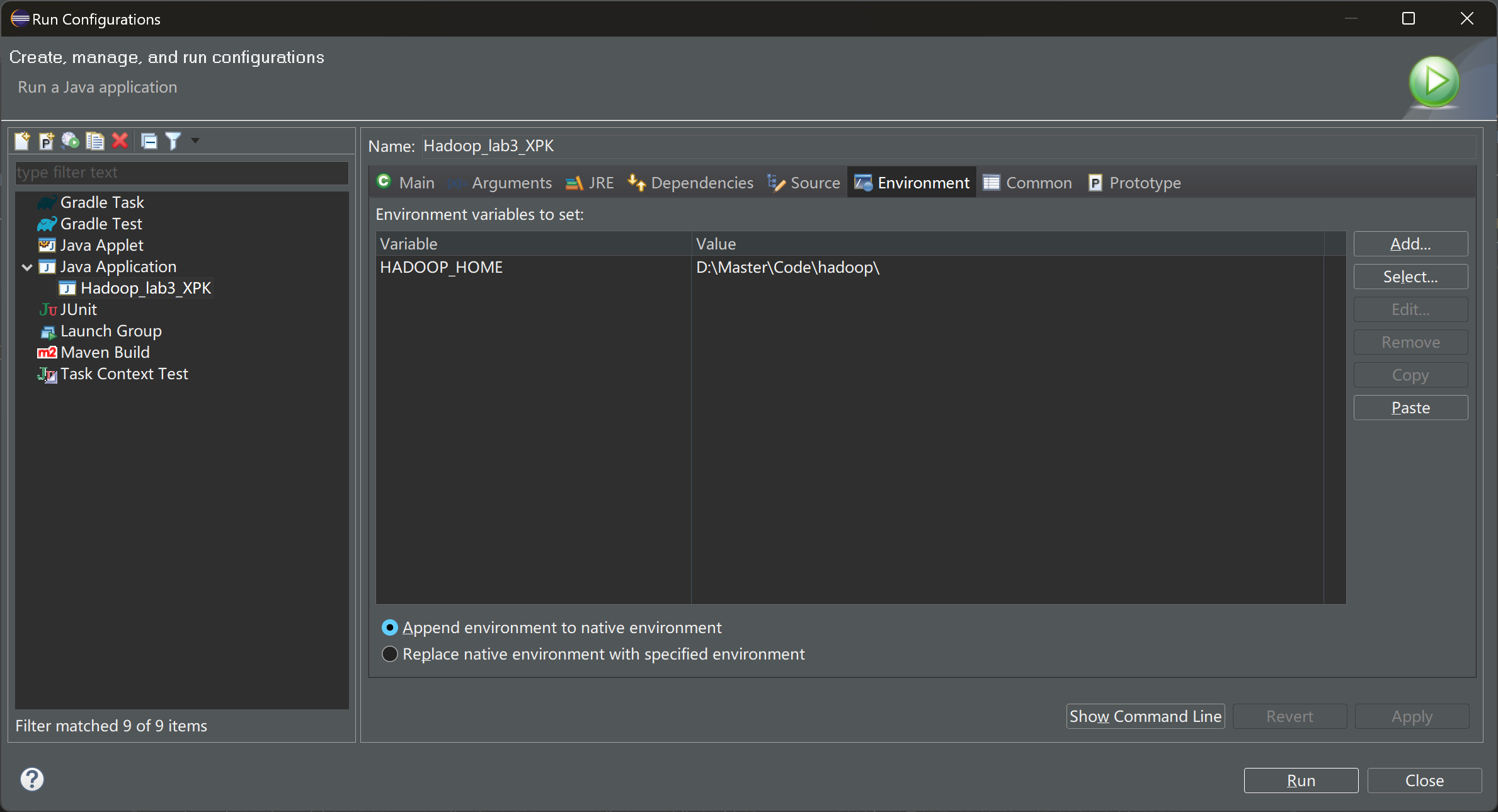
在项目运行配置中指定
HADOOP_HOME环境变量及其值:
-
参考资料
-
-
权限错误问题
1
2
3[Thread-5] WARN org.apache.hadoop.mapred.LocalJobRunner - job_local2147375942_0001
org.apache.hadoop.security.AccessControlException: Permission denied: user=23876, access=WRITE, inode="/hadoop-user":root:supergroup:drwxr-xr-x
[main] INFO org.apache.hadoop.mapreduce.Job - Job job_local2147375942_0001 failed with state FAILED due to: NA-
问题分析
这个错误表明在本地运行作业时,用户尝试写入目录
/hadoop-user时遇到权限问题,并导致作业以失败结束。 -
解决方法
在master节点中执行以下代码,以赋予当前用户对目标HDFS文件夹的写权限:
1
sudo chmod -R 777 /hadoop-user/
-
参考资料
-
评论