Hadoop 环境配置

主要步骤
一、准备虚拟机
首先要创建五台一模一样的Ubuntu虚拟机,可在VMware中先安装一个Ubuntu虚拟机,然后克隆出另外四个虚拟机。
二、搭建集群
1.修改hostname
现在有五台虚拟机,改hostname:将其中一台改作master,其余分别改作slave1、slave2、slave3、slave4。让其处于同一局域网中。
1 | sudo gedit /etc/hostname |
修改后保存。
2.记录五台虚拟机的IP地址
在终端输入ipconfig,可以得到本节点IP。最终可以得到:
1 | 192.168.242.129 master |
接下来修改节点IP映射,在每台虚拟机的hosts文件末尾添加上述IP-主机名映射(重启后生效):
1 | sudo gedit /etc/hosts |
3.ping通五台虚拟机
利用刚刚记录下来的IP地址,五台虚拟机互相ping通:
1 | ping IP地址/主机名 |
4.配置SSH免密登录
首先安装SSH:
1 | sudo apt-get install openssh-server #安装服务,一路回车 |
关闭完防火墙,接下来查看是否开通SSH服务:
1 | ps -e | grep ssh |
只要出现了以下进程就说明成功了:

接下来在master节点生成SSH公钥,公钥储存在 /root/.ssh 中
1 | sudo cd /root/.ssh |
让master 节点可以无密码 SSH 本机,在 master 节点上执行以下代码:
1 | cat ./id_rsa.pub >> ./authorized_keys |
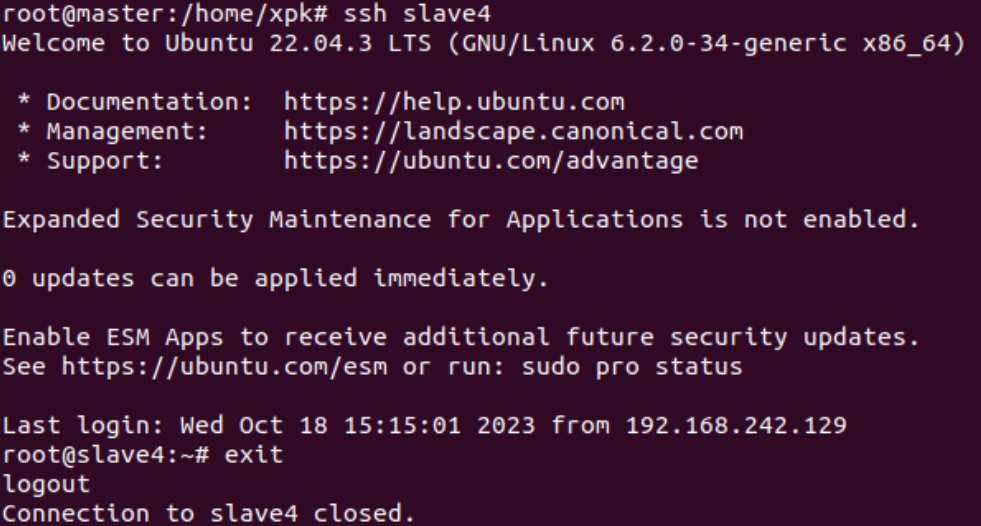
完成后可执行ssh master验证一下(需要输入 yes,成功后执行 exit 返回原来的终端)
1 | ssh master |
接着在 master 节点将上述公匙传输到 slave1 节点,过程中需要输入 slave1 节点的密码,传输100%以后就是传过去了:
1 | scp ./.ssh/id_rsa.pub xpk@slave1:/home/xpk |
接着在 slave1 节点上,把 master 节点的公钥加入授权:
1 | mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 |
在其余 slave 节点重复以上步骤,然后就可以免密码SSH所有 slave 节点了:
最后在 master 节点修改SSH文件权限(否则之后SSH免密登录可能失效):
1 | chmod 700 /root/.ssh/ #修改 .ssh/ 文件夹权限为700 |
5.安装配置JDK环境变量
下载JDK
官网: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
我下载的是 JDK1.8 ,压缩文件名为jdk-8u391-linux-x64.tar.gz。
解压tar包
把安装包放到 /usr/local/java/ 目录下面(没有java目录的话自行创建),然后解压安装包:
1 | 创建目录 |
配置JDK环境变量
修改 environment 文件:
1 | 修改文件 |
修改 profile 文件:
1 | 修改文件 |
配置立即生效:
1 | 立即生效 |
检查Java命令:
1 | 查看java版本 |
6.安装和配置Hadoop
下载Hadoop安装包
Hadoop官网:http://hadoop.apache.org/
我下载的是 hadoop3 ,压缩文件名为hadoop-3.3.6.tar.gz。
解压Hadoop安装包(只在master做)
把 Hadoop 压缩包放置到/opt/hadoop目录内,然后在 master 主机上执行以下代码:
1 | cd /opt/hadoop |
进入/opt/hadoop目录后,执行解压缩命令:
1 | tar -zxvf hadoop-3.3.6.tar.gz |
配置env文件(只在master做)
执行命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh |
找到export JAVA_HOME这行,修改为:
1 | export JAVA_HOME=/usr/local/java/jdk1.8.0_391/ |
配置核心组件文件(只在master做)
Hadoop 的核心组件文件是core-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,将下面的配置代码放在文件的<configuration>和</configuration>之间。
执行编辑core-site.xml文件的命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/core-site.xml |
需要在<configuration>和</configuration>之间加入的代码:
1 | <property> |
编辑完成后,退出并保存即可。
配置文件系统(只在master做)
Hadoop 的文件系统配置文件是hdfs-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑hdfs-site.xml文件的命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml |
需要在<configuration>和</configuration>之间加入的代码:
1 | <property> |
编辑完成后,退出保存即可。
配置yarn-site.xml文件(只在master做)
yarn 的站点配置文件是yarn-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑yarn-site.xml文件的命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml |
需要在<configuration>和</configuration>之间加入的代码:
1 | <property> |
配置MapReduce计算框架文件(只在master做)
配置文件是mapred-site.xml,在/opt/hadoop/hadoop/etc/hadoop子目录下,将下面的代码填充到文件的<configuration>和</configuration>之间。
执行命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml |
需要在<configuration>和</configuration>之间加入的代码:
1 | <property> |
编辑完毕,保存退出即可。
配置master的workers文件(只在master做)
workers 文件给出了 Hadoop 集群的 slave 节点列表,该文件十分重要,因为启动 Hadoop 的时候,系统总是根据当前workers 文件中的 slave 节点名称列表启动集群,不在列表中的 slave 节点便不会被视为计算节点。
执行编辑 workers 文件命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/workers |
加入以下代码:
1 | slave1 |
注意:删除 workers 文件中原来 localhost 那一行。
复制master上的Hadoop到slave节点(只在master做)
通过复制master节点上的 Hadoop ,能够大大提高系统部署效率。由于我这里有4个 slave 节点,所以复制4次。
复制命令:
1 | scp -r /opt/hadoop root@slave1:/opt |
配置操作系统环境变量(五个节点都做)
回到用户目录命令:
1 | cd /opt/hadoop |
然后编辑.bash_profile文件,命令:
1 | sudo gedit ~/.bash_profile |
最后把以下代码追加到文件的尾部:
1 | #HADOOP |
保存退出后,执行命令:
1 | source ~/.bash_profile |
source ~/.bash_profile命令是使上述配置生效。
提示:在其余 slave 节点使用上述相同的配置方法,配置全部 slave 节点。
创建Hadoop数据目录(只在master做)
创建数据目录,命令是:
1 | mkdir /opt/hadoop/hadoopdata |
格式化文件系统(只在master做)
执行格式化文件系统命令:
1 | hadoop namenode -format |
三、Hadoop集群的启动与关闭
1.启动和关闭Hadoop集群(只在master做)
首先进入安装主目录,命令是:
1 | cd /opt/hadoop/hadoop/sbin |
然后启动,命令是:
1 | ./start-all.sh |
如果要关闭 Hadoop 集群,可以使用命令:
1 | ./stop-all.sh |
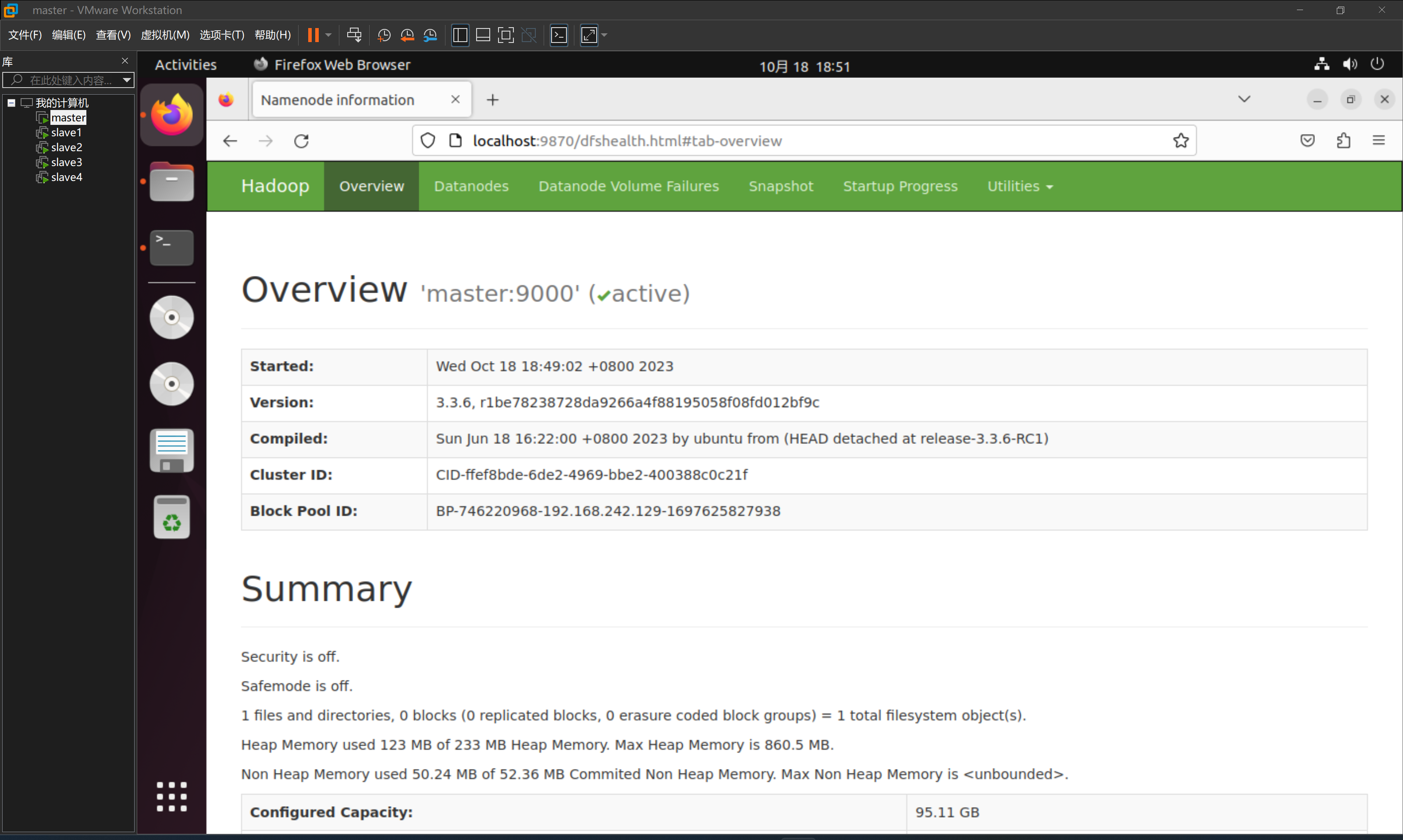
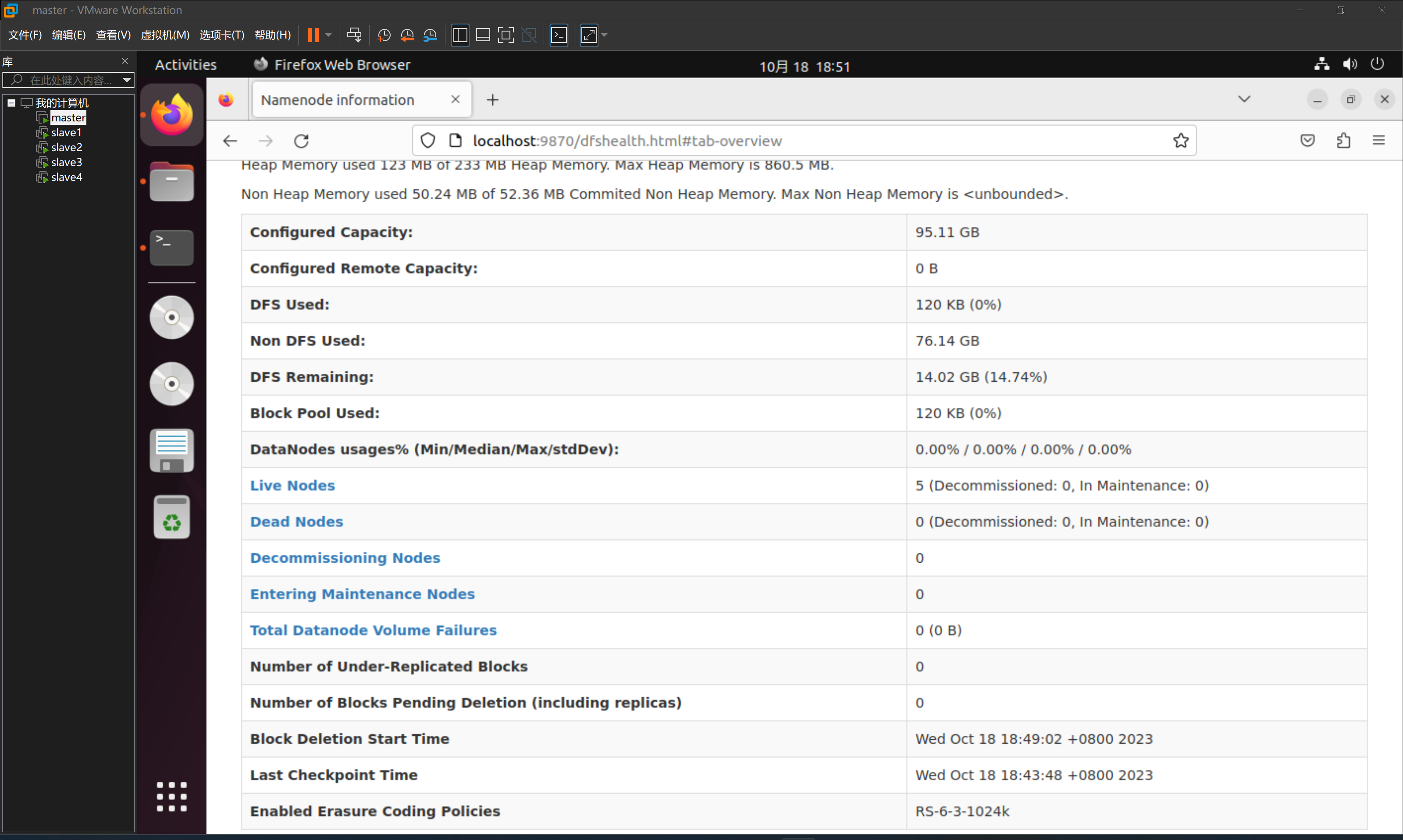
2.验证Hadoop集群是否启动成功
在 master 节点的浏览器中输入localhost:9870/并回车。打开 HDFS 面板查看详细信息:
参考资料:
遇到的 问题&解决方法
一、部分Ubuntu虚拟机无法连接网络
问题:
安装之后可以正常使用,但是隔了一段时间再上就发现有一两台虚拟机连不上网络。
解决:
1 | sudo service NetworkManager stop |
1 | sudo gedit /etc/NetworkManager/NetworkManager.conf #把false改成true |
1 | sudo service NetworkManager restart |
参考资料:
二、第一次运行Hadoop时,出现以下报错:
1 | ERROR: Attempting to operate on hdfs namenode as root |
解决:
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh中添加以下内容:
1 | export HDFS_NAMENODE_USER=root |
参考资料:
HDFS_NAMENODE_USER, HDFS_DATANODE_USER & HDFS_SECONDARYNAMENODE_USER not defined
三、主节点启动成功,从节点没有启动
解决:
执行编辑 workers 文件命令:
1 | sudo gedit /opt/hadoop/hadoop/etc/hadoop/workers |
加入以下代码:
1 | slave1 |
原因分析:
网上教程用的是Hadoop 2 版本,配置 slave 节点列表文件时修改的是slaves文件;而我使用的是 Hadoop 3 版本,Hadoop 3 版本里的配置文件需要修改workers文件,而不是slaves文件。